Python Retrieve Data From Data Frame
To retrieve multiple columns data, we can provide the list of column names as subscript to data frame object as df[ [list of column names]]. For example, to display the employee ids and their names, we can write:

Finding Maximum and Minimum Values
It is possible to find the highest value using max() method and the least value using min() method. These methods are applied to columns containing numerical data. For example, to know the highest salary and the least salary, we can use as:

Knowing the Index Range
The first column is called index column and it is generated in the data frame automatically. We can retrieve the index information using index attribute as:

Setting a column as Index
We know the index column is automatically generated. If we do not want this column and we want to set a column from our data as index column, that is possible using set_index() method. The column with unique values can be set as index column. For example, to make 'empid' column as index column for our data frame, we can write:
>>> df1 = df.set_index('empid')
The above statement creates another data frame 'df1' that uses 'empid' as index column. We can verify this by displaying df1 as:
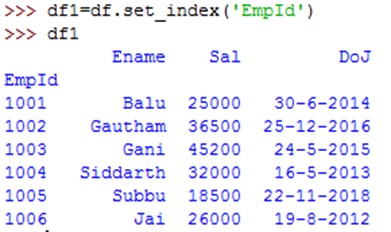
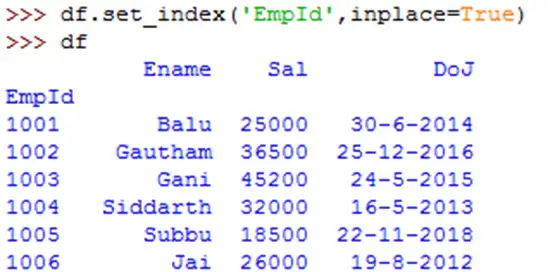
We can find the empid being used as index column in the new data frame 'df1' as above. However, the original data frame 'df' in this case is not modified and it still uses automatically generated index column. If we want to modify the original 'df' and set empid as index column, we should add 'inplace=True' as shown below:
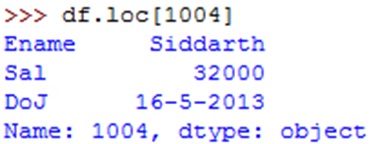
Once we set 'empid' as index, it is possible to locate the data of any employee by passing employee id number to loc attribute as:
Resetting the Index
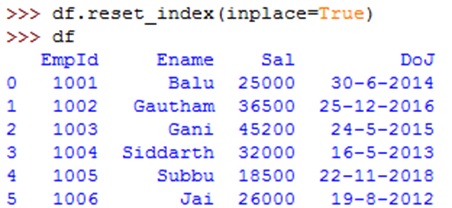
To reset the index value from 'empid' back to auto-generated index number, we can use reset_index() method with inplace=True option as: